
When I first became interested in functional programming, a more experienced engineer told me: “you know functional programming doesn’t really amount to much more than procedural programming.” As I insisted on the benefits of map, filter and reduce, he simply shook his head. “You’re thinking in the small. Go look at a large real-world application.”
It took some time for me to see what he meant. My preferred language, Clojure, is a functional language. But too often it is used to build top-down, imperative applications. This negates the value proposition of functional programming: isolating side effects, local reasoning, and system composition.
Such applications are less about a clear expression of the problem domain and more about sequential execution and mutable state.
Let’s look at an example to see what I mean.
Top Down, Imperative Architectures
Consider the following diagram of a three tiered architecture:
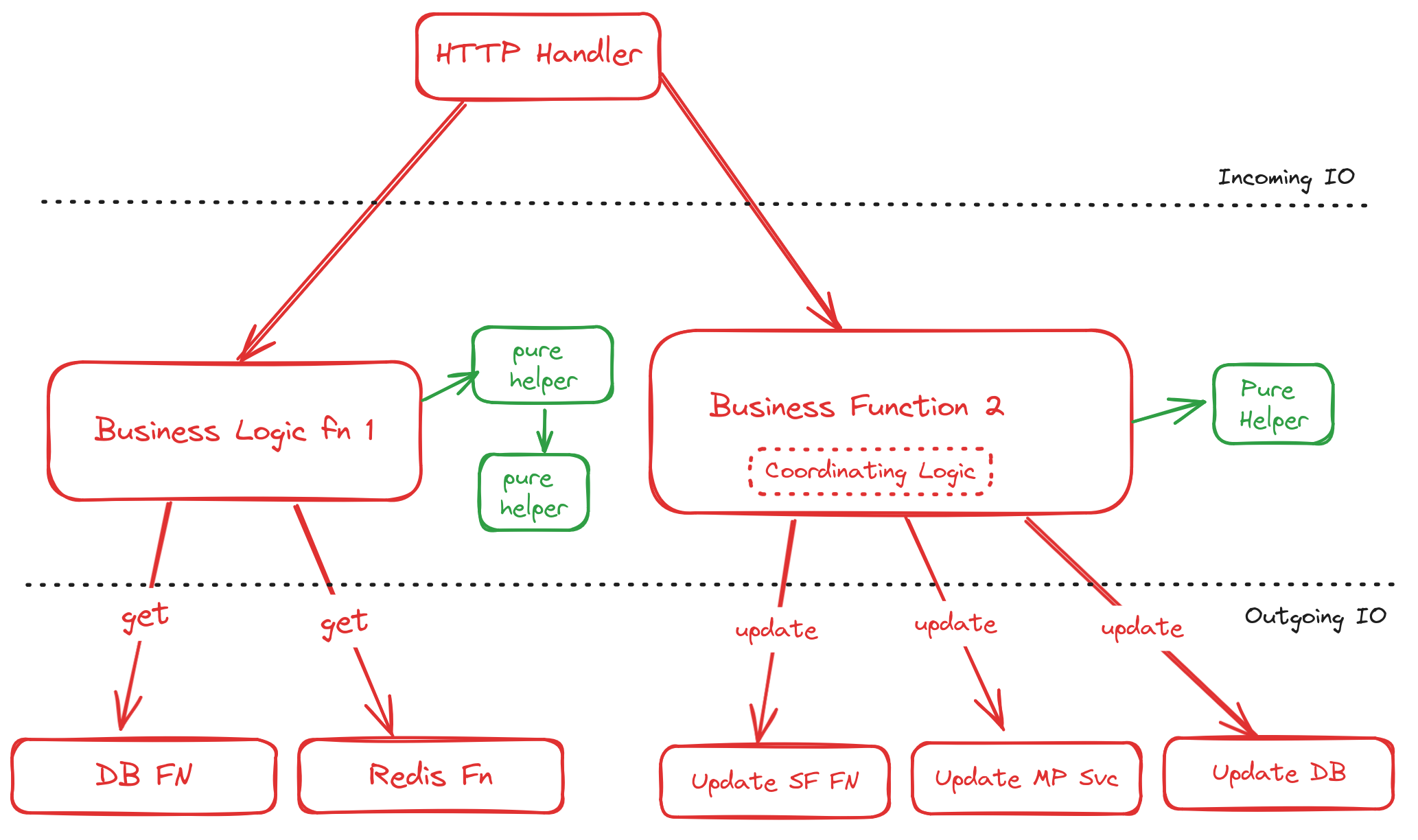
In this three-layered architecture, we have one layer dedicated to incoming requests. These could be HTTP requests or Kafka messages. The handler calls functions in the middle layer.
The middle layer invokes functions in the lower layer to fetch data from a store, applies its business logic, and then invokes more functions from the lowest layer again to persist any data. It may make calls to other services, and it will need coordinating logic to determine what happens with different errors or responses. In the case of an HTTP handler, it returns a response.
The system is imperative rather than declarative, focusing on the mechanics of the implementation rather than the business domain, with no abstraction used to separate the layers and each layer knowing the details about the one below it.
The application follows a series of sequential steps: pull this from the database, then notify this service over HTTP, etc. The application is top down, for it does not break the functionality down into composable modules. Instead it organizes its steps into procedures, concerning itself primarily with control flow and the needs (or quirks) of the data layer.
This is in contrast to what Rich Hickey suggested in Simple made Easy:
These are the things that our abstractions are going to be connected to eventually depending on how your technology works. You want to build components up from subcomponents in a sort of direct injection style. You don’t want to, like, hardwire what the subcomponents are. You want to, as much as possible, take them as arguments because that’s going to give you more programmatic flexibility in how you build things.
But our imperative system inhibits combination by hard-coding the application’s structure. For example, if I wanted to get a value from a cache rather than Postgres, I must change the code in the middle layer to do so. By contrast, if the sources were abstracted, a function in the middle layer could easily be composed with one or the other data source.
John Hughes put it this way in “Why Functional Programming Matters”:
When writing a modular program to solve a problem, one first divides the problem into subproblems, then solves the subproblems, and finally combines the solutions. The ways in which one can divide up the original problem depend directly on the ways in which one can glue solutions together.
By contrast, the imperative architecture is heavily coupled – and coupled to the data layer. Because the imperative approach has one kind of glue – direct coupling largely in the business layer, the cost and risk of change are both much higher than they need to be.
Yourdon and Constantine characterize coupling in the following way:
The more that we must know of module B in order to understand module A, the more closely connected A is to B.
Our so-called business layer has too much to do to worry about modeling the business’ domain. It needs to know all about the data sources, where they are found, and how they are called.
Although we often talk about software quality almost as though it were an aesthetic concern, tightly coupled software has an economic cost. The cost of a system is mostly in the maintenance phase, and the cost of maintenance is mostly in making large changes. What makes these changes large is tight coupling. If A can be changed without B, then A and B are not coupled with respect to that change.
This economic cost is not merely theoretical. DORA’s 2015 and 2017 reports found that high performing teams used loosely coupled architectures. “Loosely coupled architectures and teams are the strongest predictor of continuous delivery”. And although they were primarily focused on system-level architectures, empirical work on the effect of tight coupling has been carried on for years. The findings have overwhelmingly found tight coupling to be harmful.
Testability
Because the imperative architecture is tightly coupled, it is hard to test.
As Michael Feathers notes:
Can we only ever test one function or class? In procedural systems, it is often hard to test functions in isolation. Top-level functions call other functions, which call other functions, all the way down to the machine level.
The reason the system is hard to test is because it is heavily coupled to its IO layer. Most of the complexity in our example lives not in our pure helper functions, but in the middle layer calling and coordinating IO. Our business layer isn’t really about any business process, it’s more about mediating and managing IO details.
Remember the claim that functional programming gives you the benefits of pure functions? Wouldn’t it be nice to have something like that when testing?
What about with-redefs?
One tool that can be used is with-redefs. But imagine the following dialogue between two developers. Oli is steeped in object-oriented practices, Fran is a functional programming enthusiast.
Fran: you should try functional programming. It makes programming easy to reason about with referential transparency, functional purity …
Oli: that sounds appealing, but how do you manage your side effects though? You need to read from and write to a database, you probably have a cache and a message queue, and so on.
Fran: That’s the business logic. You just call the functions that handle the database.
Oli: you couple your domain logic to your IO layer? How do you test it?
Fran: we use with-redefs to mutate global variables
Developers like Fran assume that the difficulty of testing is a problem with testing itself. Fran doesn’t see that the problem is about fundamental design: loose coupling and flexibility. The testing pain is feedback on a poor design.
with-redefs is a code smell. It has other practical problems: it’s not thread-safe, it can handle macros in surprising ways, and it can clobber your spec or malli instrumentation.
Our concern here is not so much with testing, however. It’s about well-design systems that are easy to change, easy to manipulate programmatically, loosely coupled, and enable local reasoning.
Tests are useful in this context insofar as they identify bad design choices in real time.
The Upshot
The structure of an applications and systems is more consequential than the choice of a language. Unfortunately, the benefits Clojure provides can be easily suffocated under the weight of procedural architectures.
Rather than limiting IO, such architectures couple their core logic to IO. Rather than embracing composition, they ossify into a hierarchy of namespaces. Rather than facilitating testability, they make our applications unreliable. Rather than enabling change, they make change expensive.
Clojure can give composability, testability, and maintainability. Don’t let imperative, procedural architecture take that away!
Resources
If you have only worked with procedural applications in the past, here are some resources worth checking out: